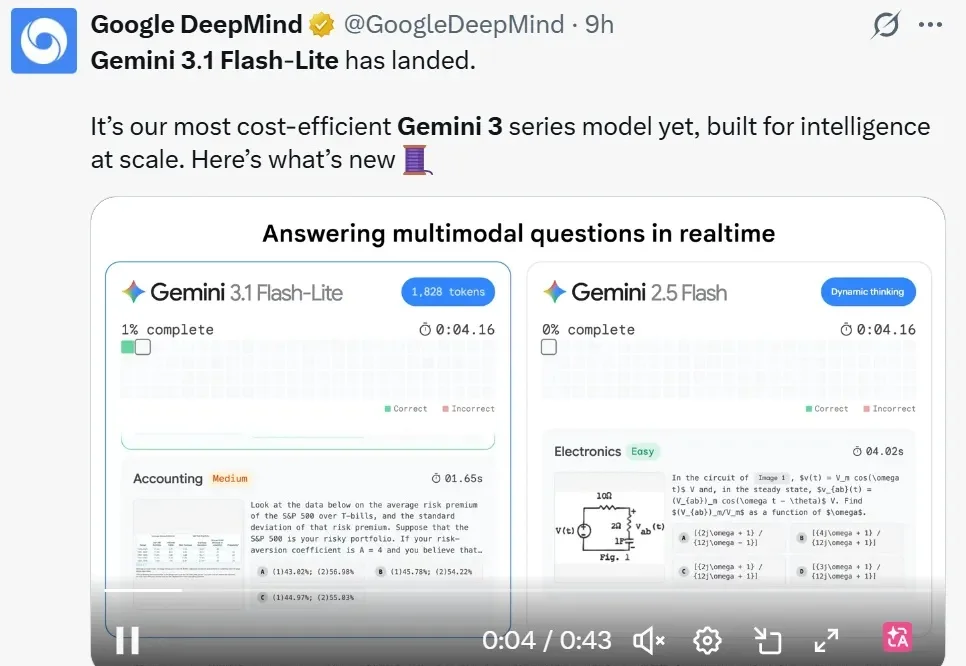
谷歌、OpenAI同日发布模型,一个最快最具性价比,一个主打「人情味」
谷歌、OpenAI同日发布模型,一个最快最具性价比,一个主打「人情味」深夜,两大科技巨头谷歌和 OpenAI 硬刚起来,相继推出了新版本大模型,分别是 Gemini 3.1 Flash-Lite、GPT‑5.3 Instant。
来自主题: AI资讯
6829 点击 2026-03-04 14:37
 搜索
搜索
深夜,两大科技巨头谷歌和 OpenAI 硬刚起来,相继推出了新版本大模型,分别是 Gemini 3.1 Flash-Lite、GPT‑5.3 Instant。

前段时间 AI 浏览器扎堆上线,从 OpenAI 的 Atlas 到 Perplexity Comet,国内的 QQ浏览器、夸克/千问纷纷进入赛道。浏览器这个「老古董」突然成了 AI 赛道的香饽饽。大小厂都在抢,都想占个入口位置。
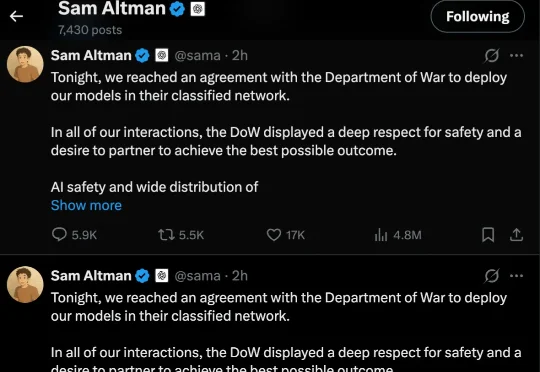
就在奥特曼公开支持 Anthropic、声称反对五角大楼施压后不到 12 小时,剧情发生了戏剧性逆转。刚刚,奥特曼在 X 上连发三条相同的帖子,宣布 OpenAI 已与美国五角大楼达成协议,将模型部署到他们的机密网络中。

此事件震动了整个硅谷。虽然此前因为抨击其他 AI 公司「蒸馏」其模型,Anthropic 成为了众矢之的,但目前 Anthropic 在科技界获得了巨大的声援。包括竞争对手 OpenAI、谷歌都公开表态支持 Anthropic 坚守底线的决定。

它叫 Patty,由 OpenAI 驱动,是汉堡王 BK Assistant 平台的语音助手。员工可以随时问它:枫糖波旁烧烤皇堡放几片培根?奶昔机怎么清洁?它都能答。设备故障或食材缺货时,系统会在 15 分钟内自动同步所有渠道——自助点餐机、得来速、电子菜单板——全部更新,不需要人工干预。

2026 年 2 月 15 日,Sam Altman 宣布:Peter Steinberger 加入 OpenAI,负责下一代个人 Agent。11 天后,Anthropic 宣布收购 Vercept。但这两件事放在一起看,说的是同一件事:AI 的战场正在发生一次非常具体的迁移——从「谁的模型更聪明」,到「谁能让 AI 真正控制一台电脑」。

上个月,我在 X 上刷到一个叫 Gabriel 的年轻人的故事。他从大学辍学,用 AI 自学人工智能,最终成为了 OpenAI 的研究员。真正吸引我的,是他在个人博客里分享的一套学习方法:「递归学习法」。

谷歌突击封杀使用开源智能体 OpenClaw 的开发者账号。这表面是打击违规算力调用,实为谷歌对 OpenAI 阵营的生态围剿。巨头筑起高墙,AI 跨平台开源红利终结,企业面临严峻的断供风险。
去年 1 月底,在一次白宫新闻发布会上,特朗普和 OpenAI CEO Sam Altman、软银 CEO 孙正义等人联合宣布了一个名为「星际之门」(Stargate Project)的人工智能项目。

作者 | 高允毅 很多人知道,Transformer 是谷歌发明的。但 ChatGPT,却不是谷歌做出来的。这件事,在过去几年,几乎成了硅谷最大的“遗憾注脚”。 但如果真正走进今天的 Google D